'분류 전체보기'에 해당되는 글 178건
- 2009.02.11 브라우저에서 한글입력이 안될때
- 2009.02.11 XML 네임 스페이스
- 2009.02.09 /proc 파일시스템으로 시스템 관리하기
- 2009.01.16 Java 프로젝트 배포하기 - JSmooth, InstallFactory
- 2009.01.16 jar파일에서 외부 패키지 사용하기
- 2009.01.16 nohup 명령어에 대한 모든 것
- 2009.01.15 JVM 메모리 구조 및 설명
- 2009.01.15 [JVMSTAT]jvmstat 3.0 설치방법
- 2009.01.14 uname 명령을 이용한 시스템 정보 확인 - Kernel 실행 Bit, Version ..
- 2009.01.14 애플리케이션 성능관리(APM) 시장 현황과 전망
- 시작 > 실행
-
Regsvr32.exe /u msimtf.dll 명령어를 실행한다.
-
Regsvr32.exe /u msctf.dll 명령어를 실행한다.
-
모든 웹브라우저를 닫고 브라우저를 새롭게 실행 후 한글 입력이 잘 되는지 확인한다.
네임 스페이스의 정의
XML문서 1 : 고객정보
<정보>
<번호>821023-1234567</번호>
<이름>홍길동</이름>
<주소>서울 영등포구 당산동</주소>
</정보>
XML 문서 2 : 상품정보
<정보>
<번호>12</번호>
<상품명>세탁기</상품명>
</정보>
위의 예제에서 각각의 문서를 사용하는데에는 문제가 없지만 두 문서의 내용을 하나의 문서로 포함될 경우 <정보>라는 동일한 엘리먼트가 중복되는 경우가 생긴다.
XML 내부에서 서로 다른 마크업 언어 사용시 동일한 이름을 가지는 엘리먼트가 각각의 마크업 언어에 존재한다면 문제발생의 가능성이 있다. 물론 엘리먼트 마다 고유한 이름을 주면 되지만 같은 이름을 부르지 않으리란 법이 있을까? 이러한 엘리먼트 이름의 충돌을 방지하기 위해서 엘리먼트 이름 앞에 서로 다른 접두사를 붙여 고유한 이름을 만든다.
네임스페이스 이름
네임스페이스 이름은 인터넷 주소인 URL 형식으로 만든다.
프로토콜명://웹서버명.도메인이름/작성년도/구체적인이름
예 : http://www.w3.org/2007/myname
네임스페이스 이름을 URL 형태로 만드는 이유는 세계적으로 유일한 이름을 부여해 주기 위해서이다.
마크업 언어가 네임스페이스 이름을 가지고 있다면 반드시 네임스페이스 선언 후 사용해야 한다.
네임스페이스 선언과 사용
<엘리먼트명 xmlns:접두사1="네임스페이스이름1"
xmlns:접두사2="네임스페이스이름2>
<접두사1:엘리먼트명/>
<접두사2:엘리먼트명/>
</엘리먼트명>
- 네임스페이스 이름은 URL형태이기때문에 태그명으로 부적합므로 접두사를 따로 만들어 사용한다.
- 네임스페이스는 접두사만 다르게 하여 중복으로 선언할 수 있다.
- 엘리먼트 이름 앞에 접두사를 붙여서 해당 네임스페이스에 속함을 표시할 수 있다.
- 선언된 네임스페이스는 해당 엘리먼트와 그 자손 엘리먼트에 한정된다.
- 접두사를 생략하고 선언하면 엘리먼트에서도 접두사를 생략할수 있다. (디폴트 네임스페이스)
- 엘리먼트에 속성이 사용된 경우 속성에도 접두사를 붙여주어야 하며, 디폴트 네임스페이스 라도 속성에는 무조건 접두사를 붙여야 한다.
- 디폴트 네임스페이스 영역에서 <엘리먼트명 xmlns=""></엘리먼트명> 을 표시하여 디폴트 네임스페이스 영역을 해제할 수 있다.
출처 : http://blog.naver.com/myshyz?Redirect=Log&logNo=50023521107
Graham White
IT 전문가, Hursley, IBM
2003년 5월 14일
/proc 파일시스템은 리눅스의 탁월한 특징 중 하나이다. 이를 통해 머신을 끄고 재부팅 하지 않고 OS의 상세한 부분들을 관리할 수 있다.
상업적으로 매우 중요한 시스템을 관리해 본 사람이라면 업타임(uptime)의 가치를 안다. 역으로 말하면 다운타임(downtime)으로 인해 사용자들로부터 듣게될 원성으로 인한 두통을 알 것이다. 기업이 유닉스 서버를 실행하는 이유 중 하나는 유닉스의 신뢰성과 안정성 때문이다. 주의 깊게 관리된다면 한 동안 재부팅 할 필요 없이 지내게 된다. 게다가 서버를 실행상태로 유지하면서 커널 레벨에서 관리 작업도 수행할 수 있다. 하드웨어를 업그레이드하기 위해 시스템을 재시작 해야 하거나 누군가가 전원 코드를 실수로 뺄 수 있다면 서비스에 피해를 주지 않고 관리작업을 수행하는 것을 알아두는 것이 좋다.
이 글에서는 재부팅 없이 다양한 관리 작업을 수행하고 시스템을 변경할 수 있는 방법이 소개되어 있다. 리눅스는 시스템을 실행 상태로 유지 시킨 채 리눅스 기저의 값과 설정을 변경하는 다양한 방법을 제공한다.
Note: 본 자료는 2.4 레벨 커널 기준이다. 일부 옵션과 기능은 다른 커널 버전과 다를 수 있다.
실행중인 커널 매개변수 변경하기
리눅스는 시스템이 실행중인 동안 커널/시스템을 재부팅 할 필요 없이 관리자들이 커널을 변경할 수 있는 깔끔한 방법을 제공한다. 이는 /proc 이라고 하는 가상 파일시스템으로 수행된다. Linux Gazette는 /proc에 관한한 가장 간단하고 쉬운 레퍼런스를 제공한다. (참고자료) 기본적으로 /proc 파일시스템은 실행 커널을 볼 수 있는 시각을 제공한다. 이는 퍼포먼스를 감시하고 시스템 정보를 발견하며 시스템이 어떻게 설정되었는지를 파악하고 그 설정을 변경할 때 유용하다. 이러한 파일시스템을 가상 파일시스템(virtual filesystem)이라고 한다. 실제 파일시스템이 아니기 때문이다. 이것은 일반적인 파일시스템 구조에 어태치된 커널에 의해 제공되어 이에 액세스 할 수 있게 한다.
시스템이 실행중일 때 실행중인 커널 매개변수를 변경하는 몇 가지 방법이 있다는 사실은 커널 설정 변경에 상당한 힘과 유연성을 시스템 관리자들에게 제공해준다고 볼 수 있다. 이러한 유형의 구현은 일부의 리눅스 커널 개발자들에게 영감을 주는 생각이었다. 하지만 힘도 너무 크면 오히려 나쁠 수도 될 수 있지 않은가? 가끔 그렇다. /proc 파일시스템에 있는 무엇인가를 변경한다면 변경하려는 것이 무엇이고 시스템에 미칠 영향에 대해 반드시 알아야한다. 이들은 실제로 유용한 기술이지만 잘못된 행동은 원치 않는 결과를 가져다 줄 수 있다. 이런 작업이 처음이거나 변경으로 인한 결과를 확신하지 못한다면 중요하지 않는 머신에 연습을 먼저 하기 바란다.
어떻게 변경 할 것인가?
우선 커널에 변경을 가하지 않는 방법을 생각해보자. /proc 파일시스템으로 곧바로 뛰어들어 텍스트 에디터에 있는 파일을 열고 변경을 수행하고 파일을 저장하면 안될 두 가지 중요한 이유가 있다:
데이터 무결성: 모든 파일들은 실행 시스템을 나타내고 있고 커널이 언제라도 이들 파일 중 어떤 것이라도 변경할 수 있기 때문에 시스템이 데이터를 실행중일 때 에디터를 열고 데이터를 변경한다면 저장을 한다고 해도 커널이 기대하는 것과 다를 수 있다.
가상 파일: 모든 파일들은 실제로 존재하는 것이 아니다. 저장된 데이터가 어떻게 동기화 될 수 있겠는가?
따라서 이러한 파일들을 변경할 때의 답은 에디터를 사용하지 않는 것이다. /proc 파일시스템에 있는 모든 것을 변경할 때 echo 명령어를 사용하고 명령행에서 온 아웃풋을 /proc 밑의 선택된 파일에 리다이렉트 해야한다:
echo "Your-New-Kernel-Value" > /proc/your/file
이와 비슷하게 /proc 에서 정보를 보고싶다면 그 목적에 맞게 설계된 명령어를 사용하거나 cat 명령어를 사용한다.
무엇을 변경 할 것인가?
/proc을 잘 사용하기 위해 커널 해커가 될 필요가 없다. 이 파일시스템의 구조에 대한 기본적인 이해만으로도 충분히 도움이 된다.
/proc에 있는 각각의 파일들은 매우 특별한 파일 권한들을 할당받았고 특별한 사용자 아이디에 의해 소유된다. 이는 매우 신중하게 수행되어 정확한 기능이 관리자와 사용자들에게 보일 수 있도록 한다. 특별한 권한이 개별 파일에 어떤 일을 수행하는지를 다음과 같이 요약했다:
Read-only: 사용자가 변경할 수 없는 파일: 시스템 정보를 나타내는데 사용됨.
Root-write: 파일이 /proc에서 쓰기가 가능하다면, 루트(root) 사용자만 쓸 수 있음.
Root-read: 일반적인 시스템 사용자는 볼 수 없고 루트 사용자만 볼 수 있는 파일.
Other: 여러가지 이유로 위 세 개의 경우가 섞인 것도 있다.
/proc에 대한 매우 광범위한 일반화는 /proc/sys 디렉토리를 제외하고 대부분 읽기 전용이라는 것을 알게 될 것이다. 이 디렉토리는 대부분의 커널 매개변수를 갖고 있으며 시스템이 실행되는 동안 변경되도록 설계되었다.
Making changes
/proc의 각 파일에 대한 정확한 정보와 사용법을 이 글에서는 다루지 않겠다. 이 글에서 다루어지지 않은 /proc 파일에 대한 자세한 정보의 경우, 최상의 소스는 리눅스 커널 소스 그 자체일 것이다. 매우 훌륭한 문서까지 포함되어 있다. /proc에 있는 다음 파일들은 시스템 관리자들에게 유용하다.
/proc/scsi
/proc/scsi/scsi
시스템 관리자로서 배워두면 가장 유용할 것 중 하나이다. 사용가능한 핫스왑(hot-swap) 드라이브가 있을 때 시스템을 재부팅하지 않고 더 많은 디스크 공간을 추가하는 방법이다. /proc을 사용하지 않고, 드라이브를 삽입할 수 있으나 시스템이 새로운 디스크를 인식하도록 하려면 재부팅해야 한다. 다음과 같은 명령어로 새로운 드라이브를 시스템이 인식하도록 할 수 있다:
echo "scsi add-single-device w x y z" > /proc/scsi/scsi
이 명령어가 올바르게 작동하도록 하려면 매개변수 값인 w, x, y, z를 정확히 해야한다:
w는 첫 번째 어댑터가 0 인 호스트 어댑터 ID 이다.
x는 첫 번째 채널이 0 인 호스트 어댑터 상의 SCSI 채널이다.
y는 디바이스의 SCSI ID 이다.
z는 첫 번째 LUN이 0 인 LUN 넘버이다.
디스크가 시스템에 추가되면 이전에 포맷된 파일시스템들을 마운트하거나 포맷을 시작할 수 있다. 디스크가 어떤 디바이스가 도리지 불확실하거나 기존에 존재하는 파티션을 점검하고 싶다면 fdisk -l 같은 명령어를 사용하면 된다.
바꿔 말하면 재부팅 필요 없이 시스템에서 디바이스를 제거하는 명령어는 다음과 같다:
echo "scsi remove-single-device w x y z" > /proc/scsi/scsi
이 명령어를 입력하고 시스템에서 핫스왑 SCSI 디스크를 제거하기 전에 디스크에서 파일시스템을 먼저 언마운트한다.
/proc/sys/fs/
/proc/sys/fs/file-max
이것은 할당받을 수 있는 최대 파일 핸들 수를 지정한다. 열린 파일의 최대 수가 다 되었기 때문에 더 이상의 파일을 열 수 없다는 에러 메시지를 사용자가 받는다면 이 값을 늘려야한다. 수는 제한 없이 설정될 수 있고 파일에 새로운 숫자 값을 작성하여 변경할 수 있다.
기본 설정: 4096
/proc/sys/fs/file-nr
이 파일은 file-max와 관련이 있고 세 개의 값을 보유하고 있다:
할당받은 파일 핸들의 수
사용된 파일 핸들의 수
최대 파일 핸들의 수
이 파일은 읽기 전용이며 정보 전달만을 목적으로 한다.
/proc/sys/fs/inode-*
"inode"라는 이름으로 시작하는 모든 파일은 "file"로 시작하는 파일과 같은 작동을 수행하지만, 파일 핸들 대신 inode와 관련된 작동을 수행한다.
/proc/sys/fs/overflowuid & /proc/sys/fs/overflowgid
이것은 16 비트 사용자와 그룹 ID를 지원하는 모든 파일시스템용 User ID (UID)와 Group ID (GID)를 갖고있다. 이 값들은 변경될 수 있지만 원하면 그룹과 패스워드 파일 엔트리를 변경하는 것이 더 쉽다.
기본 설정: 65534
/proc/sys/fs/super-max
이것은 수퍼 블록 핸들러의 최대 수를 지정한다. 마운트 한 모든 파일시스템은 수퍼 블록을 사용하여 많은 파일시스템들을 마운트하더라도 실행 될 수 있도록 할 수 있다.
기본 설정: 256
/proc/sys/fs/super-nr
현재 할당된 수퍼 블록의 수 이다. 이 파일은 읽기 전용이며 정보 전달만을 목적으로 한다.
/proc/sys/kernel
/proc/sys/kernel/acct
프로세스 어카운딩이 로그를 포함하고 있는 파일시스템 상의 빈 공간의 양을 기반을 해서 발생할 경우를 제어하는 세 개의 설정 가능한 값을 갖고있다:
빈 공간이 이 비율 이하가 되면 프로세스 어카운팅은 멈춘다.
빈 공간이 이 비율 이상이 되면 프로세스 어카운딩이 시작된다.
다른 두 개의 값이 검사되는 (초당) 빈도수.
이 파일에서 값을 변경하려면 스페이스로 분리된 숫자 리스트로 echo 해야한다.
기본 설정: 2 4 30
이 값들은 로그를 포함하고 있는 파일시스템의 빈 공간이 2% 미만이라면 어카운팅을 멈춘다. 그리고 빈 공간이 4% 이상 이라면 다시 시작한다. 검사는 30초 마다 이루어진다.
/proc/sys/kernel/ctrl-alt-del
이 파일은 시스템이 ctrl+alt+delete 키 조합을 받을 때 어떻게 반응하는지를 제어하는 바이너리 값을 갖고 있다. 두 개의 값은 다음과 같은 것을 나타낸다:
0 값은 ctrl+alt+delete가 트랩(trap)되어 init 프로그램으로 보내지는 것을 의미한다. 셧다운 명령어를 입력한 것 처럼 시스템이 정지하고 재시작하도록 한다.
1 값은 ctrl+alt+delete 트랩되지 않고 어떤 깨끗한 셧다운도 수행되지 않을 것을 의미한다. 전원을 끈 것과 같은 이치이다.
기본 설정: 0
/proc/sys/kernel/domainname
이를 사용하여 네트워크 도메인 이름을 설정할 수 있다. 기본 값이 없으며 이미 설정되었을 수도 아닐 수도 있다.
/proc/sys/kernel/hostname
기본 값이 없으며 이미 설정되었을 수도 아닐 수도 있다. 네트워크 호스트 이름을 설정할 수 있다.
/proc/sys/kernel/msgmax
이것은 하나의 프로세스에서 다른 프로세스로 보내질 수 있는 최대 메시지 사이즈를 지정한다.
기본 설정: 8192
/proc/sys/kernel/msgmnb
하나의 메시지 큐에서의 최대 바이트 수를 지정한다.
기본 설정: 16384
/proc/sys/kernel/msgmni
최대 메시지 큐 식별자의 수를 지정한다.
기본 설정: 16
/proc/sys/kernel/panic
"커널 패닉"으로 인해 재부팅 되기 전에 커널이 기다려야 할 시간을 나타낸다. 0초 설정은 커널 패닉 시 재부팅 할 수 없다.
기본 설정: 0
/proc/sys/kernel/printk
중요성을 기준으로 해서 로깅 메시지가 전송될 곳을 지정하는 숫자 값을 갖고 있다:
Console Log Level: 이 값보다 높은 우선순위를 지닌 메시지들은 콘솔에 프린트된다.
Default Message Log Level: 우선순위가 없는 메시지들은 이 우선순위로 프린트된다.
Minimum Console Log Level: Console Log Level이 설정될 수 있는 최소(가장 높은 우선순위) 값.
Default Console Log Level: Console Log Level 용 기본 값.
기본 설정: 6 4 1 7
/proc/sys/kernel/shmall
주어진 지점의 시스템에서 사용될 수 있는 총 공유 메모리 (바이트) 양.
기본 설정: 2097152
/proc/sys/kernel/shmax
커널에 허용된 최대 공유 메모리 세그먼트 사이즈 (바이트)를 지정한다.
기본 설정: 33554432
/proc/sys/kernel/shmmni
전체 시스템을 위한 최대 공유 메모리 세그먼트의 수.
기본 설정: 4096
/proc/sys/kernel/sysrq
0이 아닐 때 System Request Key를 활성화한다.
기본 설정: 0
/proc/sys/kernel/threads-max
커널에서 사용할 수 있는 최대 쓰레드의 수.
기본 설정: 2048
/proc/sys/net
/proc/sys/net/core/message_burst
새로운 경고 메시지를 작성하는데 필요한 시간 (1/10 초); 이 시간동안 받은 다른 경고 메시지들은 누락된다. 시스템을 메시지로 넘쳐나게 하려는 사람들의 "Denial of Service" 공격을 방지하는데 사용된다.
기본 설정: 50 (5초)
/proc/sys/net/core/message_cost
모든 경고 메시지와 관련된 비용의 값을 보유하고 있다. 값이 높을 수록 경고 메시지가 더욱 무시된다.
기본 설정: 5
/proc/sys/net/core/netdev_max_backlog
인터페이스가 커널이 처리할 수 있는 것보다 빠른 패킷을 받았을 때 큐에 허용된 최대 패킷 수를 제공한다.
기본 설정: 300
/proc/sys/net/core/optmem_max
소켓 당 할당된 최대 버퍼 사이즈를 지정한다.
/proc/sys/net/core/rmem_default
수신 소켓 버퍼의 기본 사이즈(바이트) 이다.
/proc/sys/net/core/rmem_max
수신 소켓 버퍼의 최대 사이즈(바이트) 이다.
/proc/sys/net/core/wmem_default
송신 소켓 버퍼의 기본 사이즈(바이트) 이다.
/proc/sys/net/core/wmem_max
송신 소켓 버퍼의 최대 사이즈(바이트) 이다.
/proc/sys/net/ipv4
모든 IPv4와 IPv6 매개변수는 커널 소스 문서에 모두 문서화되었다. /usr/src/linux/Documentation/networking/ip-sysctl.txt 파일을 참조하기 바란다.
/proc/sys/net/ipv6
IPv4와 같다.
/proc/sys/vm
/proc/sys/vm/buffermem
버퍼 메모리에 사용될 총 시스템 메모리(퍼센트) 양을 제어한다. 파일에 공간 분리 리스트를 작성하여 설정될 수 있는 세 개의 값을 갖고 있다:
버퍼에 사용될 최소 메모리 비율.
남아있는 시스템 메모리가 적을 경우 시스템 메모리가 없어질 때 시스템은 이 정도의 버퍼 메모리를 유지하려고 한다.
버퍼에 사용될 최대 메모리 비율.
기본 설정: 2 10 60
/proc/sys/vm/freepages
시스템이 다른 레벨의 빈 메모리에 어떻게 반응할 것인지를 제어한다. 공간 분리 리스트를 파일에 작성하여 설정할 수 있는 세 개의 값이 있다:
시스템에서 비어있는 페이지의 수가 최소 한계에 다다랐다면 커널에만 더 많은 메모리를 할당하도록 허용된다.
시스템에서 비어있는 페이지의 수가 이 한계 밑으로 떨어지면 커널은 공격적으로 빈 메모리로 스와핑을 시작하며 시스템 퍼포먼스를 유지한다.
커널은 이 정도의 시스템 메모리를 빈 상태로 유지할 것이다. 이 밑으로 떨어지면 커널 스와핑이 시작된다.
기본 설정: 512 768 1024
/proc/sys/vm/kswapd
커널이 메모리를 스와핑하도록 어떻게 허용할 지를 제어한다. 공간 분리 리스트를 파일에 작성하여 설정할 수 있는 세 개의 값이 있다:
커널이 한번에 빈 공간으로 둘 최대 페이지의 수. 스왑으로 대역폭을 늘리려면 이 숫자를 늘린다.
각 스왑에 대해 커널이 페이지를 빈 곳으로 유지하는 최대 시간.
한 스왑에서 커널이 작성할 수 있는 페이지의 수. 이것은 시스템 퍼포먼스에 가장 큰 영향을 미친다. 값이 클수록 스와핑 될 데이터는 많아지고 디스크 검색에 사용되는 시간은 줄어든다. 하지만 값이 너무 크면 시스템 퍼포먼스에 역효과를 가져온다.
기본 설정: 512 32 8
/proc/sys/vm/pagecache
/proc/sys/vm/buffermem과 같은 작업을 수행하지만 메모리 매핑과 일반적인 파일 캐싱을 위해 작동한다.
영속적인 커널 설정
/proc/sys 디렉토리에는 어떤 커널 매개변수라도 변경할 수 있도록 편리한 유틸리티가 있다. 이를 사용하여 실행 커널을 변경할 수 있지만 시스템 부트에서 실행되는 설정 파일 또한 있다. 이것은 실행 커널을 변경하고 그들을 설정 파일에 추가시켜 시스템 재부팅 후에도 어떤 변경이라도 남아있게 된다.
이 유틸리티는 sysctl 이라고 하며 sysctl(8)의 맨페이지에 모두 문서화 되어 있다. sysctl용 설정 파일은 /etc/sysctl.conf이며 편집 될 수 있다. sysctl.conf(8)에 문서화되어 있다. Sysctl은 /proc/sys 밑에 있는 파일들을 변경될 수 있는 개별 변수들로 취급한다. 따라서, 예를 들어, 시스템에 허용된 최대 파일 핸들의 수를 나타내는 /proc/sys 밑의 파일인 /proc/sys/fs/file-max는 fs.file-max로 나타난다.
이 예제는 sysctl 표기에서 몇 가지 이상한 점을 드러낸다. sysctl은 can only change variables under the /proc/sys 디렉토리 밑에 있는 변수들을 변경할 수 있기 때문에 변수 이름의 일부는 이 디렉토리 밑에 있는 것으로 가정되는 변수로서 무시된다. 디렉토리 분리자(슬래시, /)는 마침표(.)로 변경되었다.
/proc/sys 에 있는 파일들과 sysctl의 변수들 간 변환에 적용되는 두 개의 간단한 규칙이 있다:
시작부터 /proc/sys를 누락한다.
파일이름에서 슬래시를 마침표로 바꾼다.
이 두 개의 규칙으로 /proc/sys에 있는 모든 파일 이름을 sysctl의 모든 변수 이름으로 바꿀 수 있다. 변수 변환에 대한 일반적인 파일은 다음과 같다:
/proc/sys/dir/file --> dir.file
dir1.dir2.file --> /proc/sys/dir1/dir2/file
변경될 수 있는 모든 변수들을 볼수 있고 이에 더하여 sysctl -a 명령어를 사용하여 그들의 현재 설정을 볼 수 있다.
sysctl를 사용하여 변수들이 변경될 수 있는데 이는 위에 사용된 echo 메소드와 같은 작업을 수행한다:
sysctl -w dir.file="value"
file-max 예제를 다시 사용하여, 다음과 같이 두 개의 메소드 중 하나를 사용하여 이 값을 16384로 변경할 수 있다:
sysctl -w fs.file-max="16384"
또는:
echo "16384" > /proc/sys/fs/file-max
sysctl은 설정 파일을 변경하지 않음을 기억하라. 수동으로 하도록 남겨두었다. 재부팅 후에도 변경을 영속성있게 유지하려면 이 파일을 유지하라.
Note: 모든 배포판이 sysctl을 지원하는 것은 아니다. 이는 특정 시스템의 경우이며, 시스템 부팅 시 실행되도록 하려면 위에 설명된 에코와 리다이렉트 메소드를 사용하여 시작 스크립트에 이 명령어를 추가한다.
시스템 설정을 위한 명령어
시스템이 실행되는 동안 다른 비커널 시스템 매개변수를 변경하고 또한 재부팅 필요 없이 설정을 발효시킬 수 있다. 이들은 주로 서비스, 데몬, 서버로 분류되며 /etc/init.d 디렉토리에 있다. 이 디렉토리에 리스팅될 수 있는 스크립트가 점점 광범위해지기 때문에 여기에서 모든 다양한 설정을 다루기엔 불가능하다. 아래 몇 가지의 예제는 /etc/init.d 스크립트가 다양한 리눅스 배포판에서 어떻게 조작될 수 있는지를 설명하고 있다. 재부팅 필요 없이 설정 데몬과 리로드를 변경하는 것은 유용한 예제이다:
웹 서버 설정 변경과 Apache 리로딩
원하지 않는 inetd 로그인 서비스 제거
네트워크 설정 조작
NFS를 통한 새로운 파일시스템 반출
방화벽 시작/중지
우선, 시스템 서비스를 조직하는 일반적인 방법은 직접 /etc/init.d에 있는 스크립트를 통해서이다. 이 스크립트들은 매개변수를 취하여 그들이 제어할 서비스를 조작한다. 유효한 작동이 무엇인지 보기위해 매개변수 없이 스크립트 이름을 입력할 수 있다. 일반적인 매개변수들은 다음과 같다:
start: 중지된 서비스 시작
stop: 실행되는 서비스 중지
restart: 멈춘 후 실행 서비스 시작. 또는 중지된 서비스 시작
reload: 연결을 끊지 않은 채 서비스 설정 리로드
status: 서비스의 실행 여부를 나타내는 아웃풋
예를 들어 다음의 명령어는 연결된 사용자 세션을 종료하지 않고 xinetd 설정을 리로드 한다:
/etc/init.d/xinetd reload
Red Hat은 service 명령어를 제공하는데 이는 서비스를 조작한다. service 명령어는 스크립트 이름을 타이핑할 때와 같은 기능을 제공한다. 신택스는 다음과 같다:
service script-name [parameter]
예를 들어:
service xinetd reload
SuSE 역시 rc 라는 명령어를 제공한다. 이는 서비스 명령어와 비슷하다. 하지만 명령어와 스크립트 이름 사이에 공간이 없다:
rc{script-name} parameter
예:
rcapache start
[출처] http://ttongfly.net/zbxe/?mid=linuxsys&search_target=title&search_keyword=%2Fproc&document_srl=43116&listStyle=&cpage=
 invalid-file
invalid-fileInstallFactory : 배포파일 만들기 --> 첨부파일
 invalid-file
invalid-file사람이 밥만먹고 살 수는 없듯이, 프로그램을 짜다보면 외부 jar파일을 이용해야 하는 경우가
수시로 생기게 된다. 문제는, 내가 짠 프로그램을 jar파일로 배포해야 할때도 내가 사용했던
외부 jar파일이 필요하게 된다는 것이다.
내가 만든 jar파일에서 외부 jar파일을 사용해야 한다면 어떤 방법이 가장 좋을까..
내가 생각하기에는 내 jar파일을 만들때 외부 jar파일도 함께 묶고 Class-Path를 잘 지정해
주는것이 가장 좋은 방법이 아닐까 싶다. 이렇게 해놓으면 내 jar파일 내부에 있는 클래스들이
외부 jar파일을 참조할 수 있고, 외부 jar파일역시 내 jar파일 외부로 나와있어서 실수로 삭제되거나
하는 일이 발생하지 않는다.
그런데, 문제는 java의 jar파일은 이러한 기능을 지원하지 않는다는 것이다. 아래는 jar Document
부분의 Class-Path에 관한 내용의 일부이다.
===========================================================================
Note: The Class-Path header points to classes or JAR files on the local file system, not JAR
files within the JAR file or classes on the network
=> Class-Path header 부분에는 사용자의 컴퓨터 내부의 class파일이나 JAR파일은 이용할 수
있지만 JAR파일 내부, 또는 network 상의 JAR파일이나 class파일들은 사용할 수 없습니다.
===========================================================================
이 글에서 볼 수 있듯이 java에서는 jar파일 내부의 jar파일에 대해서 Class-Path를 지원해 주지
않는다. 즉, jar파일 내부에 외부 jar파일을 위치시켜 놓고 프로그램이 무난히 작동되기를 바랄 수
없다는 뜻이다.
그렇다면 어떻게 외부 jar파일을 이용할 수 있을까. 크게 두가지 방법이 있다.
1) 외부 jar파일의 압축을 풀고, 압축이 풀린 class들을 내 jar파일에 묶어버리는 방법
2) 외부 jar파일을 내 jar파일의 내부가 아닌 외부에 위치시켜 놓고 Class-Path를 설정하는 방법
접두부(다른명령의 앞에 오는 명령)명령의 하나이다.
따라서 해당 명령을 지속적으로 실행하고자 할때 사용된다.
[syntax]
nohup 명령어 &
[예제]
$ nohup sleep 400 & <== 명령실행
[1] 7026
$ Sending output to nohup.out <== nohup의 표준출력파일이 생성된다.
이제 로그아웃해본다.
ctrl + d
$ There are running jobs. <== 작업이 있다고 알려준다.그래도 로그아웃한다.
ctrl + d
다시 로그인 한다.
$ ps -ef| grep user6
user6 7026 1 0 15:52:03 ? 0:00 sleep 400 <== 실행중이군여..
user6 7049 7029 14 15:53:00 pts/tg 0:00 ps -ef
user6 6769 6768 0 14:12:12 pts/tc 0:00 -sh
user6 7050 7029 3 15:53:00 pts/tg 0:00 grep user6
user6 7029 7028 0 15:52:38 pts/tg 0:00 -sh
$
[Tip]
:: nohup 명령의 출력방향을 지정하지 않으면 Default로 nohup.out이라는 파일이
생성된다. 이파일에는 표준출력과 표준에러가 모두 기록된다.
[참고] http://cafe.daum.net/itcome/FJLr/238?docid=h1oj|FJLr|238|20080919184010&q=nohup&srchid=CCBh1oj|FJLr|238|20080919184010
JVM의 메모리 구조를 좀 알아둘 필요가 생겨서 찾아봤다.
응용프로그램이 실행되면, JVM은 시스템으로부터 프로그램을 수행하는데 필요한 메모리를 할당받고 JVM은 이 메모리를 용도에 따라 여러 영역으로 나누어 관리한다.
그 중 3가지 주요영역(Method Area, 호출스택, Heap)에 대해서 알아보도록 하자. 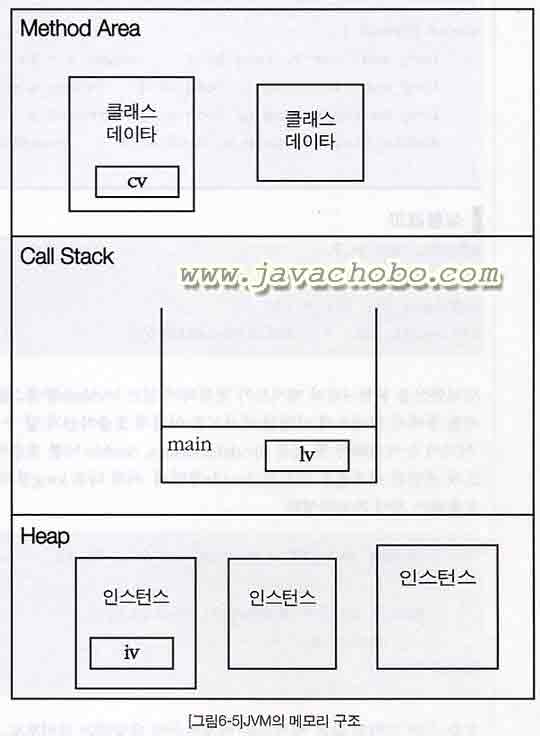
[참고] cv는 클래스변수, lv는 지역변수, iv는 인스턴스변수를 뜻한다.
이 때, 그 클래스의 클래스변수(class variable)도 이 영역에 함께 생성된다.
각 메서드를 위한 메모리상의 작업공간은 서로 구별되며, 첫 번째로 호출된 메서드를 위한 작업공간이 호출스택의 맨 밑에 마련되고, 첫 번째 메서드 수행중에 다른 메서드를 호출하게 되면, 첫 번째 메서드의 바로 위에 두 번째로 호출된 메서드를 위한 공간이 마련된다.
이 때 첫 번째 메서드는 수행을 멈추고, 두 번째 메서드가 수행되기 시작한다. 두 번째로 호출된 메서드가 수행을 마치게 되면, 두 번째 메서드를 위해 제공되었던 호출스택의 메모리공간이 반환되며, 첫 번째 메서드는 다시 수행을 계속하게 된다. 첫 번째 메서드가 수행을 마치면, 역시 제공되었던 메모리 공간이 호출스택에서 제거되며 호출스택은 완전히 비워지게 된다.
호출스택의 제일 상위에 위치하는 메서드가 현재 실행 중인 메서드이며, 나머지는 대기상태에 있게 된다.
따라서, 호출스택을 조사해 보면 메서드 간의 호출관계와 현재 수행중인 메서드가 어느 것인지 알 수 있다.
호출스택의 특징을 요약해보면 다음과 같다.
- 언제나 호출스택의 제일 위에 있는 메서드가 현재 실행 중인 메서드이다. - 아래에 있는 메서드가 바로 위의 메서드를 호출한 메서드이다. |
반환타입(return type)이 있는 메서드는 종료되면서 결과값을 자신을 호출한 메서드(caller)에게 반환한다. 대기상태에 있던 호출한 메서드(caller)는 넘겨받은 반환값으로 수행을 계속 진행하게 된다.
| [예제6-6] CallStackTest.java |
| secondMethod() class CallStackTest { public static void main(String[] args) { firstMethod(); } static void firstMethod() { secondMethod(); } static void secondMethod() { System.out.println("secondMethod()"); } } |
| [실행결과] |
위의 예제를 실행시켰을 때, 프로그램이 수행되는 동안 호출스택의 변화를 그림과 함께 살펴보도록 하자
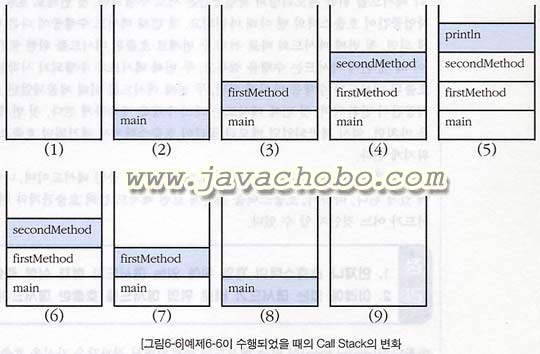
(1)~(2) 위의 예제를 컴파일한 후 실행시키면, JVM에 의해서 main메서드가 호출됨으로써 프로그램이 시작된다. 이때, 호출스택에는 main메서드를 위한 메모리공간이 할당되고 main메서드의 코드가 수행되기 시작한다.
(3) main메서드에서 firstMethod()를 호출한 상태이다. 아직 main메서드가 끝난 것은 아니므로 main메서드는 호출스택에 대기상태로 남아있고 firstMethod()의 수행이 시작된다.
(4) firstMethod()에서 다시 secondMethod()를 호출했다. firstMethod()는 secondMethod()가 수행을 마칠 때까지 대기상태에 있게 된다. seoundMethod()가 수행을 마쳐야 firstMethod()의 나머지 문장들을 수행할 수 있기 때문이다.
(5) secondMethod()에서 println메서드를 호출했다. 이때, println메서드에 의해서 화면에 "secondMethod()"가 출력된다.
(6) println메서드의 수행이 완료되어 호출스택에서 사라지고 자신을 호출한 secondMethod()로 되돌아간다. 대기 중이던 secondMethod()는 println메서드를 호출한 이후부터 수행을 재개한다.
(7) secondMethod()에 더 이상 수행할 코드가 없으므로 종료되고, 자신을 호출한 firstMethod()로 돌아간다.
(8) firstMethod()에도 더 이상 수행할 코드가 없으므로 종료되고, 자신을 호출한 main메서드로 돌아간다.
(9) main메서드에도 더 이상 수행할 코드가 없으므로 종료되어, 호출스택은 완전히 비워지게 되고 프로그램은 종료된다.
| [예제6-7] CallStackTest2.java |
class CallStackTest2 { public static void main(String[] args) { System.out.println("main(String[] args)이 시작되었음."); firstMethod(); System.out.println("main(String[] args)이 끝났음."); } static void firstMethod() { System.out.println("firstMethod()이 시작되었음."); secondMethod(); System.out.println("firstMethod()이 끝났음."); } static void secondMethod() { System.out.println("secondMethod()이 시작되었음."); System.out.println("secondMethod()이 끝났음."); } } |
| [실행결과] |
| main(String[] args)이 시작되었음. firstMethod()이 시작되었음. secondMethod()이 시작되었음. secondMethod()이 끝났음. firstMethod()이 끝났음. main(String[] args)이 끝났음. |
/// 또다른 아티클..
Java Virtual Machine의 메모리 관리
전통적인 C언어나 C++언어와는 달리 자바에서는 메모리 관리는 프로그래머가 일일이 하지 않고 JVM에서 알아서 관리 해 줍니다.(물론 닷넷의 경우엔 자바와 비슷한 방법으로 하지만)
메모리 관리란 크게 보면 생성/소멸(삭제, 반납)의 과정으로 생각 할 수 있는데 우리가 자바 프로그램에서 Hello h = new Hello(“방가방가”) 라고 하든지 아님 int i=10; 이라고 할 때 메모리의 일정 부분을 할당 받게 되는 것입니다. 메모리에서 할당이 필요해지면 JVM은 변수에 대해 실제의 내용을 포인터로써 관리를 해주게 됩니다. JVM이 모든 객체의 레퍼런스를(참조) 카운트하고 관리하기 때문에 메모리 영역의 충돌이나 삭제 하지 않은 메모리 때문에 memory leak등이 발생 할 가능성이 거의 없어 졌습니다.
HOT SPOT이전의 JVM(JIT기반, JDK1.3 이전)에서는 메모리에 대한 간접 참조 방식을 이용하였는데 아시는 것 처럼 간접 방식이므로 실제 내용을 찾아 가기 위해서는 두번이상의 참조가 일어나게 됩니다. 물론 조금은 느려질 소지가 있었겠지요~ 이 경우엔 오히려 Garbage Collection시에는 참조만 지우면 되므로 오히려 간단했다고 볼 수 있습니다.
간접 참조란 힙에 객체의 내용이 있다면 중간에 그곳을 가리키는 메모리 영역이 있고(핸들 메모리) 스택에 있는 변수가 핸들 메모리를 참조해서 실제 힙의 주소를 얻은 후 힙의 실제 내용을 참조하게 되는 방식 입니다. 반면 직접 참조의 경우 스택에 있는 변수가 힙메모리의 실제 주소를 가지고 있어 직접 참조 하게 되는 방식 입니다. 그러므로 자주 참조되는 변수나 객체가 있다면 직접 참조 방식이 훨씬 뛰어난 성능을 보입니다.
반면에 가비지컬렉션의 경우(메모리를 지우거나 참조값을 바꾸는 경우) 직접 참조 방식에서는 값이 없어지거나 사라져야 하는 변수에 대해 일일이 포인터를 지워줘야 합니다. 반면 간접 참조 방식의 경우 핸들 메모리만 수정을 해주면 되므로 오히려 간단해 지는 것입니다.
Virtual Machine에서는 스택과 힙 메모리를 사용하며 스택에는 프로그램에서 사용하는 변수, 함수명등이 수행 순서에 맞게 적재 되어 있고 힙 메모리에는 실제 스택에 있는 변수나 함수의 내용이 적재 됩니다. 즉 스택에는 실제 값이 존재하는 곳의 포인터를 가지므로 크기가 크지 않으나 힙의 경우 사용량이 커지게 됩니다. 만약 힙 메모리를 다써버린 다면 java.lang.OutOfMemory 오류가 발생 할겁니다.
이번에는 메모리의 해제에 대해 보도록 하겠습니다. 아까 위에서 만든 객체 참조변수에 대해 h = null; 이라고 하는 경우나 어떤 메소드 안에 쓰인 변수가 메소드의 실행이 종료하게 되는 경우에 메모리에서 해제 될 것 입니다.
JVM의 힙메모리에는 프로그램 실행시 생성된 여러 값들이 존재 합니다. 가비컬렉터가 하는 일은 이러한 힙 메모리중 사용하지 않는 메모리를 반환 시키는 역할을 하는 것입니다. 위의 경우 처럼 h = null; 이라고 명시적으로 지정 하는 경우 객체 헤더에 존재하는 GC(Garbage Collector) 필드가 값이 설정 됩니다. 이렇게 지정 된 객체에 대해 우선적으로 메모리에서 삭제를 하게 됩니다.
반면 스코프를 벗어나는 경우 Local 변수는 다음과 같은 조건에 따라 삭제 여부를 판단하게 됩니다. 스택 메모리에 있는 변수 중 해당 객체에 대한 참조가 있는 경우 또는 객체가 메모리에 있다는 이야기는 다음에 있을 확률이 높다는 판단(이게 LRU방식 맞나여??)을 JVM에서 해(일반적으로 프로그래밍에서 사용된 객체의 95% 이상이 생성된 후 곧 삭제된다는 가정 하에 아직까지도 있는 객체이므로 필히 중요한 것 일꺼야 하는 기술을 Generation Copying Collection이라 합니다) 가급적 가비지 컬렉션을 수행 하지 않습니다. 또는 정적 혹은 현재 스코프의 객체가 해당 객체를 참고 하고 있는 경우, JVM내부에서 사용하는 네이티브 메소드에 사용되는 객체에 해당 하는 경우 등은 가비지 컬렉션에서 제외를 하며 기타의 경우엔 메모리에서 삭제를 하게 됩니다. 대부분의 프로그래밍 언어에서 사용된 객체는 거의 금방 소멸 된다는 것 때문에 Java에서는 메모리를 두가지 영역으로 메모리를 나누는데 Young 영역과 Old 영역으로 나눕니다. Young 영역은 생긴지 얼마 안된 객체들을 저장하는 장소이고, Old영역은 생성된지 오래된 객체를 저장하는 장소 입니다. 각 영역의 성격이 다른 만큼 GC의 방법 또한 다릅니다. 또한 Perm 영역이라고 불리는 곳이 있는데 이곳에는 클래스나 메소드의 실행 코드가 저장 됩니다. 그래서 GC가 일어나는 곳은 old, new 영역이며 Perm영역은 GC가 수행 되지 않습니다.(소스 코드가 있으므로)
JDK1.3 이상에서 탑재된 HOT SPOT VM의 경우(병목 현상이 일어날 확률이 높은 부분을 먼저 컴파일) 가비지 컬렉션에 따른 성능 저하를 막기 위해 Generation Copying Collection 기술을 이용하여 가비지 컬렉션 대상을 줄였으며 Incremetal Pauseless 기법을 이용하여 가비지컬렉션 대상을 여러 개의 작은 그룹으로 나누어 확실히 삭제 가능한 객체부터 지워나가는 방식을 채택 했습니다. Incremetal Pauseless 기법에서는 1차 가비지 컬렉션 대상은 객체의 헤더에 GC 필드가설정된 것이고 2차 대상은 위의 4가지 유형에 속하지 않은 것 입니다. 2차 대상의 경우 일단 CG필드를 설정 하고 다음번 가비지 컬렉션 주기에 삭제 되는 것 입니다.
# java JVM Memory Perf 분석
- Tools : jvmstat-5.zip
J2SE 1.5 이상
- 구성 환경 :
Host A에 설치 동작중인 Java Applicaton( Unix )에 대한 메모리 이용율을
Host B( Windows )에서 Remote로 확인
- Host A 설치내용
J2SE 1.5 이상의 버젼이 설치 되었는지 확인
참고 : Java 1.5부터는 jvmstat의 내용이 일부 포함되어 배포가 됨.
jvmstat를 위한 Home Directory 생성 ( /usr/local/jvmstat )
$ mkdir /usr/local/jvmstat/
RMI Connection 권한 설정 파일 생성
$ cd /usr/local/jvmstat/
$ vi jstatd.all.policy
grant codebase "file:${java.home}/../lib/tools.jar" {
permission java.security.AllPermission;
};
jvmstat를 위한 환경 변경 설정
$ export JAVA_HOME=/usr/local/java
$ export JVMSTAT_HOME=/usr/local/jvmstat
$ export PATH=$JVMSTAT_HOME/bin:$JAVA_HOME/bin:$PATH
jstatd 실행 ( jvmstat 2.0의 perfagent와 같음. )
$ cd /usr/local/jvmstat/
$ cat start.sh
#!/bin/bash
export JVMSTAT_HOME=/usr/local/jvmstat
export JAVA_HOME=/usr/local/jdk1.5.0_02
export PATH=$JAVA_HOME/bin:$JVMSTAT_HOME:$PATH
# RMI Registry Start
$JAVA_HOME/bin/rmiregistry &
# JSTAT PerfAgent Start
nohup \
$JAVA_HOME/bin/jstatd \
-J-Djava.security.policy=$JVMSTAT_HOME/jstatd.all.policy \
-J-Djava.rmi.server.logCalls=true \
&
$ sh start.sh
local test 수행
$ jps
$ jstat -gcutil 11216 1000 10 ( 11216은 jvmps에서 vmid )
Java RMI Connection을 위한 설정
$ vi /etc/hosts
위 hostname ( backup )을 RMI로 호출될 Interface의 IP로 변경 한다.
127.0.0.1 localhost.localdomain localhost
192.168.1.117 backup
- Host B 설치 내용
J2SE 1.5 이상의 버젼이 설치 되었는지 확인
jvmstat-3.zip를 C:\에 압축 풀기 ( visualgc에 대한 내용만이 포함되어 있음. )
jvmstat를 위한 환경 변경 설정
SET JAVA_HOME="C:\Program Files\Java\jdk1.5.0_02"
SET JVMSTAT_HOME="C:\jvmstat"
SET JVMSTAT_JAVA_HOME="C:\Progra~1\Java\jdk1.5.0_02"
SET PATH=%JVMSTAT_HOME%\bat;%JAVA_HOME%\bin;%PATH%
remote test 수행 ( Host A와의 RMI 통신여부 확인 )
C:\jvmstat\bat\> jps 192.168.1.117
C:\jvmstat\bat\> jstat -gcutil rmi://11216@192.168.1.117 1000 10
- Host A의 Java Application 모니터링
상기의 설치 내용이 정상적으로 완료 확인
Host B에서
C:\jvmstat\bat\> visualgc 11216@192.168.1.117:1099 5000
11216 : vmid
192.168.1.117 : host A's IP Address
1099 : Host A's RMI TCP Port
5000 : Interval , millisecond
uname 명령을 이용한 시스템 정보 확인 - Kernel 실행 Bit, Version ..

# uname 또는 uname -s =kernel 실행 bit, KERN_POINTERS "IRIX64"
# uname -n = Hostname "irix"
# uname -r = operating system release "6.5"
# uname -R = hardware specific release "6.5 6.5.30m"
# uname -v = OS 설치 시간 "mmddhhmm" 형식 출력 "07202013"
# uname -m = machine hardware "IP30"
# uname -a = -mnrsv 옵션을 모두 사용 "IRIX64 irix 6.5 07202013 IP30"
애플리케이션 성능관리 시장 현황과 전망
하이테크정보 2007년 12월 송년호 Market Center 란에 이원영대표의 기고글
애플리케이션성능관리(APM) 솔루션 등장배경
90년대 후반, 인터넷의 급속한 보급과 더불어, 기업환경은 기존의 클라이언트/서버(C/S) 시스템으로부터 보다 유연하고 사용자의 접근성을 향상하기 위해 웹 기반 시스템으로 급격히 전환 되어왔다. 웹기반 운영 환경의 핵심적인 미들웨어로 자리잡은 웹어플리케이션서버(WAS) 시장은 1998년도부터 2003년까지 매년 초고속 성장을 하여 국내 500억원 시장을 형성하였고, 자바(JavaTM)언어가 기존의 4세대(4GL)언어를 지속적으로 대체하면서 현재 상당수의 기업 소프트웨어 인프라 환경은 J2EETM 기반으로 운영되고 있다.
이러한 J2EE/WAS 시장의 성장은 그 성장 속도가 지나칠 만큼 빨랐고, 4GL언어에 익숙한 선배 개발자와 그 이후 자바 언어 세대인 후배 개발자들 사이에는 상당한 기술적 단절이 일어나는 과정에서 지난 수 십년 동안 이어져 내려오던 메인프레임과 클라이언트/서버 환경에서의 안정적인 시스템 운영방침이나 탄탄한 소프트웨어 개발을 위한 개발 지침 등이 제대로 전수되지 못했다. 프로젝트가 진행됨에 따라 개발이 끝나고 서비스 오픈이 임박한 상황에서도 성능적인 차원에서 정상적인 운영이 가능할 지가 기술적으로 예측 불가능하게 됐고, 용량산정 또한 적절히 검증할 수 있는 절차나 방법을 찾아내지 못했다. 특히나, 시스템 관점에서의 자원사용량은 충분한데도 불구하고 사용자가 증가함에 따라 서비스 응답시간이 지연될 경우, 애플리케이션 내부에서 일어나는 일련의 서비스 과정을 세밀하게 모니터링하지 않으면 근본적인 해결책을 찾을 수 없는 상황이 발생하곤 했다. 산업표준 없이 개발된 각양 각색의 소프트웨어 프레임워크(Framework)와 이를 기반으로 구현된 소프트웨어 시스템은 2000년 IMF 이후 양산된 기술인력 공급업체들로부터 상대적으로 경험이 풍부하지 않은 개발자에 의해 개발돼 왔고, 박복한 예산과 납기일에 쫓겨 제대로 된 성능테스팅 과정조차 거치지 않은 채 시스템 오픈이 감행됐으며, 그러한 시스템은 여지없이 시스템 오픈 첫 날 성능장애로 이어졌다. 그리고 그 후속 처리는 시스템 담당자의 몫으로, 개발업체의 몫으로, WAS 제품 납품업체의 몫으로 돌아갔지만, 실상 최대의 피해자는 직접적인 성능 장애로 인해 대외적 이미지 손상과 금전적 손실을 맞이한 그 시스템의 주인인 고객이었다. 이런 과정은 애플리케이션성능관리(APM, Application Performance Management)라는 솔루션이 탄생한 배경이 됐다.  [그림1] WAS시장과 APM시장
[그림1] WAS시장과 APM시장
웹로그분석 솔루션
초기 애플리케이션성능관리(APM)라는 개념은 지금과는 사뭇 달랐다. 1998년부터 2001년까지는 초기 웹시스템의 태동과 더불어 웹서버의 로그(log)파일을 분석하여 응답시간을 추출하는 웹로그 분석툴이 우후죽순 격으로 생겨났다. 웹로그 파일로부터 사용자의 정보 및 요청한 서비스명, 서비스처리시간 등을 확인함으로써, 어떤 서비스에서 응답지연이 일어나고 있는지를 판별해 내고, 접속되는 사용자의 규모와 지리적 위치를 파악하는 데에 활용할 수 있었다. 그러나, 웹로그분석 솔루션은 단지 웹로그 파일 기반으로 추출한 정보이기에 특정 서비스가 느리다는 것은 일정부분 확인할 수 있었지만, 성능저하 현상을 개선하기 위해서 어떻게 해야하는가하는 근본적인 서비스 지연현상의 원인을 제공하진 못했고, 결국 시간이 지남에 따라 점차 고객의 실무자로부터 외면되었다. 마지막까지 시장에 남아 있던 웹로그분석 솔루션들은 새로운 시장 돌파구를 찾기 위해 점차 고객관계관리(CRM) 솔루션으로 변화해 갔으며, 현재는 성능관리솔루션으로서의 웹로그분석 솔루션은 시장에서 찾아보기 힘들다.
네트워크기반 가용성측정 솔루션
2000년 초반, 최초로 애플리케이션성능관리(APM)라는 용어로 시장에 새롭게 등장한 솔루션 군이 있었다. 네크워크 패킷을 분석하거나 혹은 특정 네트워크 망에 임의로 설치되어 선택적으로 지정된 애플리케이션을 주기적으로 호출하여 그 응답시간을 측정하고 24시간 시스템 가용성 및 사용자 응답시간의 변화, 네트워크 구간별 서비스시간을 측정해 주는 솔루션이 그것이었다. 외산 솔루션 뿐만 아니라, 국산 솔루션들도 대거 시장에 등장했다. 앞서 웹로그분석 솔루션보다 한차원 높은 서비스 모니터링이 가능하게 되었고, 단일 트렌젝션 내에서의 네트워크 구간별 응답 지연 현상을 찾아낼 수 있게 되었다. 그러나, 이러한 솔루션들은 실제 서비스가 운영되는 시스템 내부적 현상을 모니터링 하는 것이 아니라, 여전히 외부에서 바라볼 수 있는 정보만 제공해 주었기에, 애플리케이션 내부에서 일어나는 서비스 병목 원인은 찾아주진 못했다. 결국, 네트워크기반 가용성 검증 솔루션들은 어느 정도 시장에서 반향은 일으켰으나 성능관리시장에서 중심을 이루기엔 한계가 있었다.
프로파일링 솔루션의 등장
그 다음으로 대두된 솔루션은 프로파일링(Profiling) 솔루션이었다. 프로파일링이란 개념은 자바가상머신(JVM)의 내부 수행 내역을 클래스/메소드별로 응답시간, 메모리, CPU사용량을 보다 상세하게 추적하여 통계적인 결과를 트리(Tree)구조로 보여주는 것이다. 볼랜드(Borland)사의 옵티마이즈잇(OptimizeIt), 케이엘그룹(KL Group)의 프리웨어(Freeware) 제품인 제이프로브(JProbe)가 대표적이었다. 제이프로브(JProbe)는 상용소프트웨어로 치부되기엔 부족한 면이 있었으나, 광범위하게 개발자들 사이에서 사용되었고, 결국 2002년말 퀘스트소프트웨어(Quest Software)사에 5천만달러($51.7M)에 인수되었다. 그러나 그 시기 가장 앞선 기법과 기술을 가진 솔루션은 단연 볼랜드사의 옵티마이즈잇(OptimizeIt) 이었다. 이 시기부터 볼랜드사는 기존의 컴파일러 기술과 4GL제품인 델파이, 비지브로커(VisiBroker) 코바(CORBA), 웹어플리케이션서버 시장을 뒤로한 채 또다시 인수한 투게더소프트 모델링시장과 애플리케이션라이프사이클관리(Application Lifecycle Management)를 근간으로 한 성능관리분야에도 진출하기 시작했다. 그러나, 이러한 프로파일링 솔루션은 결정적인 단점을 안고 있었다. 상세한 프로파일링을 위해서는 JVMPI(Java Virtual Machine Profiler Interface) 기술을 이용하는데, 이는 성능저하가 극심했다. 개발서버에 적용하여 애플리케이션 튜닝에는 활용할 수 있었으나 부하량이 높은 실제 서비스 운영환경에서는 극심한 성능저하로 인해 사실상 적용할 수 없었다. 개발자로부터는 호평을 받았지만 시스템 운영 실무자에게는 별다른 감흥을 주지 못했다. 결국 이러한 솔루션은 일부 명맥은 현재까지 남아 있으나 지금은 이미 APM시장의 중심부에서 저만치 멀어져 있다.
애플리케이션성능관리(APM) 솔루션의 자리매김
2002년 말부터 현재 통용되는 APM이라는 용어가 자리매김하면서 2003년도부터 본격적인 변화가 일어났다. 스토리지 전문업체이던 베리타스(VERITAS)사가 프리사이스사를 인수하면서 APM시장을 공략하기 시작했고, 조직과 인력을 강화했다. 그 제품이 현재의 시만텍 아이쓰리(i3, 구 베리타스i3) 제품의 모태이다. 또한, 머큐리인터액티브사는 전세계 독보적인 성능테스트솔루션 로드런너(LoadRunner) 제품의 성공과 함께 시스템 및 애플리케이션 관리솔루션인 토파즈(Topaz) 제품도 APM 범주로 취급하기 시작하였고, 컴퓨웨어(Compuware)사 또한 분산 애플리케이션 트레픽 및 응답속도 측정이 가능한 밴티지(Vantage) 솔루션을 기업은행에 공급하는 등 국내 APM시장은 새로운 활기를 띠기 시작했다. 그러나, 이 시기에 가장 주목해야할 제품은 미국 켈리포니아 브리즈번에 위치한 와일리테크놀러지(Wily Technology)사의 와일리(Wily)라는 솔루션이었다. 한국의 펜타시스템테크놀러지사가 독점총판을 하였고, SK텔레콤, KT, 현대홈쇼핑, 국민은행, 신한생명, 동부생명, 우리은행, 삼성화재, 외환은행, 증권예탁원 등 한국 APM시장은 와일리의 독주로 이어졌다. 와일리테크놀러지사의 디크 윌리엄스 사장은 “한국시장은 웹기반 업무시스템이 급격히 성장하면서 시장잠재력이 매우 높은 지역”이라며, 매년 두배 이상의 신장을 기대했다고 전해진다.
이러한 APM시장은 2004년 중반까지 지속적으로 심화되어 갔다. 한국베리타스는 현대백화점에 자사의 베리타스 아이쓰리(i3) 솔루션을 공급하면서 와일리에 대한 윈백전략을 시도하였다. 국내업체인 아이피엠에스(iPMS)사는 데이터베이스 모니터링솔루션인 디비와인(DB WINE)과 함께 웹기반 APM솔루션인 웹와인(WEB WINE)을 개발하여 시장진출을 준비하고 있었다.
APM시장의 외면
그런데, 2004년 중후반부터 국내 APM시장은 또 다시 고객으로부터 외면받기 시작했다. 그때 당시 시장점유률이 가장 높았던 와일리 제품은 고객 시스템의 응용애플리케이션 복잡도가 높아진 상황에서 다양한 형태로 발생하는 성능장애의 실질적인 원인을 분석하고, 즉시적인 실시간 서비스 모니터링을 요구하는 까탈스런 국내 고객의 요구사항을 모두 해결해 줄 수는 없었다. 웹애플리케이션서버가 일정 부분 이미 제공하는 WAS모니터링항목을 좀더 쉽게 단일의 통합화면으로 구성하여 일괄적으로 모니터링 할 수 있다는 것과 응답이 느린 트렌젝션에 대해 메소드(Method) 구간별 점유시간을 보여주는 등 여러 장점에도 불구하고 실질적인 도입효과에 대한 고객의 반응은 그다지 긍정적이지는 않았다. WAS운영 실무자는 다양한 형태로 나타나는 성능장애의 직접적인 원인 분석 등 보다 실질적인 결과를 요구했고, 개발자는 애플리케이션코드의 오류를 자동으로 검출해 주길 바랬으며, 관리자는 일일방문자수, 동시단말사용자수, 서비스 애플리케이션별 부하량 통계 등 서비스관점의 통계성 집계를 원했다. 기존에 도입되었던 상당수 고객사의 APM솔루션은 점차 실무자의 관심에서 벗어나 형식적인 모니터링 관제 PC의 화면으로만 남아있었다. WAS기반 시스템의 심각한 성능장애가 발생하여도 이 때까지의 APM솔루션은 그 역할을 핵심적으로 해 내고 있지 못했던 것이다.
시만텍 아이쓰리(i3)
국내APM시장에서 2005년은 격동의 해였다. 한국베리타스사는 베리타스 아이쓰리(i3) 영업강화를 위해 국내업체인 케이와이즈(KWISE)와 총판계약을 맺었다. 베리타스 아이쓰리(i3)는 웹서버, WAS서버, DB서버 등 다계층 아키텍쳐 상에서 유기적인 추적 모니터링이 가능하다는 End-to-End 모니터링 전략을 매우 큰 장점으로 갖고 있다. 그러나 결정적으로 국내 고객들이 선호하는 실시간 서비스 모니터링의 관점을 전혀 갖고 있지 않아 국내시장 확대에 어려움을 겪고 있었다. 이에 대한 대안으로 협력업체인 케이와이즈는 베리타스 아이쓰리(i3)와 연동되는 실시간 모니터링 모듈인 알티엠(RTM) 모듈을 개발하여 아이쓰리(i3) 제품과 함께 공급하기 시작했다. 연이어 7월경, 보안전문업체이던 시만텍(Symantec)사가 전격적으로 베리타스 본사를 103억달러에 인수함에 따라 베리타스 아이쓰리(i3)는 시만텍 아이쓰리(i3)로 개명됐다. 케이와이즈와 함께 농협중앙회에 i3와 RTM을 함께 공급하면서, 현재까지 CJ홈쇼핑, 삼성물산, 신한은행, 싸이버로지텍, 하이닉스반도체, 국세청, 한국철도공사, 재경부, 학술진흥재단 등 꾸준히 APM시장을 점유해 나가고 있다.
자바서비스컨설팅 제니퍼(Jennifer)
2005년도부터 가장 주목받았던 APM솔루션은 자바서비스컨설팅의 제니퍼(Jennifer)였다. 실시간 통합 서비스 모니터링 기능과 성능장애 원인분석 부분에서 타사 솔루션에 비해 실질적인 도입효과와 제품활용도가 높다는 시장의 반응이 나왔다. 무엇보다 외면받았던 국내 APM솔루션 시장을 다시금 “APM”이라는 단어로 집결시키는데에 제니퍼가 실질적인 견인차 역할을 했다는 데에 이견을 제시할 업체는 없을 것이다. 고객의 개발자와 실무자로부터 실질적인 도입효과를 끌어냄으로써, 2005년 17고객사, 2006년 10월 말 현재까지 62개 고객사에 납품하여 총 79고객사를 확보하였다. (2007년 3월30일 현재 제니퍼 누적고객사수 100여군데로 증가됨.) [그림2] 제니퍼 고객사
[그림2] 제니퍼 고객사
국민은행, 기업은행, 한국은행, 산업은행, 전북은행, 기업데이타 등 굵직한 제1금융권과 LG카드, BC카드, 철도청, 제일화재, 동부화재, 효성캐피탈, 대우증권, 현대해상, 푸르덴셜, 메트라이프, 효성캐피탈, 에이스화재 등 제2금융권, 그리고, SK텔레콤, GS홈쇼핑, 인터파크, CJ홈쇼핑/엠플온라인, 특허청, 통계청, 철도청, 병무청, 산업자원부, 마사회, SK엔카, 나라신용정보, KT&G 등 쇼핑몰/제조/통신/공공 전 산업 분야에 걸쳐 제니퍼가 납품되어 자바서비스컨설팅의 금년시장 매출은 38억원이 예상되고 있다. 특히 국민은행, 기업은행 등 타 APM솔루션을 사용해 오고 있는 상황에서 제니퍼를 추가로 도입한 고객도 있다는 것은 남다른 의미를 부여하고 있다.
APM솔루션 도입 효과
APM솔루션을 도입하면 서비스 다운타임을 최소화하고 지속적인 성능모니터링을 통해 장애대응능력을 확보하게 된다. 또한 정량화된 성능 근거자료를 통해 향후 시스템 증설시 보다 정확한 용량산정을 기반으로 총소유비용(TCO)를 낮출 수 있다. 또한 IT서비스 전체적인 실시간 통합 관제센터를 구축할 수 있으며, 시스템 자원뿐만 아니라 비즈니스데이타 또한 비주얼 모니터링이 가능하다. 안정적인 시스템 운영과 즉시적인 의사결정의 근거로 사용되어 궁극적으로 대 고객 서비스 만족도를 향상시키게 된다.
국내 APM시장은 이미 도입을 위한 검토/검증단계는 지났다. 충분한 레퍼런스가 확보됐고, 먼저 적용한 고객으로부터 가시적인 도입효과를 얻었기 때문이다. 
[그림3] APM솔루션 도입효과
[그림4] 제니퍼 통합 모니터링 기본화면
[그림5] 통합대시보드 구성화면 예제
[그림6] 통합대시보드 예제/시스템모니터링
IT관리시장과 APM시장의 융합
IT인프라환경이 더 이상 기반시설로서의 역할이 아닌 회사의 생존 및 매출과 직결되는 현재의 상황에서, IT환경을 얼마나 효율화하고 최적화시킬 것인가의 문제는 오늘 날 IT기업의 최대 화두로 알려져 있다. 기업 내부의 IT프로세스 혁신을 통해 비즈니스현황을 실시간 모니터링함으로써 보다 빠른 의사결정을 내리는 실시간기업환경(RTE)으로의 체질 개선이 중요하기에, ITSM(IT서비스관리, IT Service Management)의 방향성은 틀리지 않으며 지속적으로 진화될 것으로 예상된다. 또한 ITSM 전체 개념 중 핵심적인 요소인 실질적인 애플리케이션 내부의 비즈니스 서비스를 실시간 모니터링해야 하는 요구사항이 발생하게 되었고, ITSM업체는 APM솔루션업체를 끌어 안을 수 밖에 없었다. 2006년, IT관리솔루션 업체의 APM시장 흡수는 예정대로 급속히 일어났다. 하드웨어, 소프트웨어, 메인프레임 환경에서의 애플리케이션 및 IT자산관리 전문업체인 CA사는 와일리사를 3억7천5백만달러에 인수했다. HP사는 로드런너/토파즈 제품을 보유하고 있는 머큐리인터액티브사를 45억달러에 인수했다. 기존 HP의 오픈뷰(OpenView) 시스템관리솔루션에 머큐리인터액티브의 소프트웨어관리솔루션을 결합하여 시너지를 창출할 수 있을 것으로 보이며, 무엇보다 이러한 움직임은 최근 IT업계에서 화두가 되고 있는 ITSM 시장의 조기선점을 획득하려는 것으로 보인다. 현재 ITSM시장은 시스템관리솔루션(SMS) 업체를 중심으로 점차 확대 재생산되고 있다. 다만, ITSM시장은 아직은 개념도입단계에 머물러 있기에 구체적인 실체가 존재하고 있지는 않다. 따라서, 조심스럽게 향후 ITSM시장의 변화를 예의주시해 볼 필요가 있다.
뒤틀린 AMS시장
일각에서는 APM솔루션 도입만으로는 자사의 다양한 애플리케이션관리를 하기엔 부족하다하여 애플리케이션관리시스템(AMS) 프로젝트를 시스템통합(SI)을 통해 인력을 투입하여 개발하는 경향이 있다. 단기적으로는 적절한 솔루션이 없거나, 있더라도 구미에 맞는 모든 관리 기능을 제공하지 않을 터이니 직접 개발하여 운영하자는 것이다. 그러나, 막대한 돈을 들여 개발해 둔 SI성 AMS시스템에 대한 활용도가 결과적으로 다소 저조한 것으로 알려져 적잖은 우려의 목소리가 나오고 있다. 시스템의 운영환경은 지속적으로 변화하고, 변경/추가되는 애플리케이션 및 시스템에 종속적이지 않으면서 손쉬운 설정만으로 유연하게 변화에 대응할 수 있는 IT통합서비스관제인프라 기능을 제공해 주는 적절한 솔루션을 통한 해결이 궁극적으로 바람직할 것으로 예상된다. 그러한 관점에서, IT대시보드 프로젝트, AMS프로젝트를 가이드하고 수행하는 바람직한 형태의 AMS컨설팅 시장의 안정화가 매우 필요한 시점이라 할 수 있다.
2007년 국내 APM시장 전망
자바서비스컨설팅의 제니퍼, 시만텍사의 아이쓰리(i3), CA사의 와일리, 컴퓨웨어사의 밴티지, 아이피엠에스사의 퍼포마이져(구 웹와인), EDS코리아의 파인웹, 퀘스트소프트웨어(Quest Software)사의 제이브로브(JProbe)와 최근 출시한 퍼포마슈어(PerformaSure) 등이 2006년 국내시장에서 거론되고 판매된 APM솔루션이다. 단일 APM제품만을 놓고 보았을 때 금년 38억원 시장매출과 총 79고객사를 확보한 자바서비스컨설팅의 독주현상이 일어났고, 그 뒤를 이어 시만텍 아이쓰리(i3)가 선전한 한해였다. 이러한 구도는 2007년에도 더욱 고착화 될 것으로 전망되며, 금년 60-80억 시장에서 80-100억시장으로 성장이 예상된다.
초기 APM시장 선도주자였던 CA사의 와일리는 최근 외환은행 수주에 성공하는 등 여전히 선전하고 있으나 제니퍼의 시장 영향력으로 일정부분 주춤하고 있는 형국이다. 그러나 장기적으로 CA사에 인수된 와일리는 전세계 시장에서는 기존보다 강화된 영향력을 행사할 수 있을 것으로 예상되지만, 국내의 경우는 한국CA사와 펜타시스템테크놀러지사의 전략적 역할 분담에 따라 방향성이 달라 질 수 있겠다. 한국CA사로서는 자사가 보유한 2,000여개의 솔루션 중 하나로 인식될 가능성이 높아 시장 확산 의지가 약화될 가능성이 높고, 결국 펜타시스템케크놀러지사의 와일리 국내 독점 총판 계약의 지속성 여부에 따라 방향성이 결정될 것으로 보인다.
컴퓨웨어사의 밴티지는 운영되는 서버측의 애플리케이션 내부 흐름을 추적하는 것이 아니라, 사용자 측의 PC에 설치되어 최종사용자의 네트워크 응답시간을 측정해 주는 기법을 이용하는 것으로, 일정 부분 시장에서 지속될 것으로 보인다. 컴퓨웨어사는 실제 운영되는 시스템에는 별도의 모듈을 설치할 필요가 없다는 에이전트레스(agent-less) 방식을 마케팅의 전면에 내세워 기술적 장점으로 주장한다. 그러나, 에이전트레스 방식은 실제 애플리케이션 서비스가 동작하는 서버 내부의 흐름을 모니터링할 수 없기에 성능저하의 원인을 보다 현실적으로 제공하지 못한다는 단점을 가지고 있기도 하다. 어쨌든, 이러한 최종사용자 응답측정 방식의 솔루션은 현재 형성된 APM제품군에서 이미 한발짝 비껴선 형국으로 평가된다.
볼랜드사의 옵티마이즈잇은 2006년도에 제품라인업을 중단하고 소스코드를 한국 회사인 오오씨(OOC)사에 팔았으며, 새로운 변모를 시도하지 않는 한 단기적으로 APM시장의 중심부로 다시 진입하긴 어려울 것으로 전망된다. 개발단계에서부터 운영단계까지 전체적인 애플리케이션라이프사이클관리에 대한 매력적인 마케팅 시도만큼이나 그에 따른 탄탄한 제품군을 재생산하는 것이 가장 시급할 것으로 인식된다.
아이피엠에스사의 퍼포마이져나 EDS코리아의 파인웹은 일정 부분 공공시장에서 선전할 것으로 기대되나, 제1금융권을 중심으로 한 미션크리티컬한 업무시스템에 광범위한 사용이 일어나기엔 현재의 APM시장구도에서 어렵지 않겠느냐는 전망이 우세하다.
퀘스트소프트웨어사의 퍼포마슈어(PerformaSure) 역시 한국시장에서 아직은 인지도가 낮지만 어떻게 영업전략 및 마케팅을 구사하고 영업채널망을 탄탄하게 확보하느냐에 따라 향방은 충분히 달라질 수 있을 것으로 판단된다.
티맥스소프트사의 시스마스터(SysMaster)는 아직까지는 본 글에서 거론하고 있는 APM제품군으로 분류하기에는 한계가 있다. 자사 WAS 솔루션인 제우스(JEUS) 통합콘솔 및 서비스제어 기능, 무엇보다 자사솔루션인 TP모니터 티맥스(Tmax) 및 차세대 프레임워크인 프로프레임(ProFrame) 기반 시스템의 통합서비스관리콘솔로의 면모를 갖추고 있으며, 시스마스터는 아직 웹로직(WebLogic), 웹스피어(WebSphere)등 타사 WAS솔루션에 탑재되지 않는 것으로 알려져 있다.
APM시장, 틈새시장의 탈피
APM시장은 2년을 주기로 변화해 왔다. 지난 2년은 투명하게 예상되는 성장 과정의 시기였다면, 앞으로의 2년은 상대적으로 예측 불가능하다. 핵심적인 APM솔루션 업체들은 대부분 더 큰 IT기업에 인수합병되었고, ITSM이라는 새로운 개념의 대두와 시스템관리솔루션(SMS) 시장까지 APM시장과 융화되고 있기 때문이다. 한국에서의 지난 2년의 APM시장이 틈새시장이었다면 앞으로의 2년은 더 이상 틈새시장이 아닌 굵직한 하나의 획을 긋는 100억원 규모의 핵심시장으로 전장터의 위치가 바뀌어 갈 것이다. 국내 WAS시장이 450억-500억시장인 점을 감안하면, 이는 설득력이 더욱 있어 보인다.
APM시장, 무엇을 준비할 것인가
사전영업시 필요한 문서상의 요건맞추기에 급급하지 말아야 할 것이다. 2년 정도의 시간이 흐르면 충분한 고려를 통해 도출되지 않은 요식적 기능요건은 자연스럽게 시장에서 정화되어 사라진다. 진정 필요한 기능이 무엇인지, 어떻게 모니터링하고 어떻게 분석하는 것이 가장 효율적인 것인가를 고민하고, 다소 그것이 시장에서의 통상적인 관점에서 어색할지언정 시일이 지나면 그 진가는 반드시 인정된다. 자바서비스컨설팅의 제니퍼가 나름대로 빠른 시간내에 성장할 수 있었던 비결이 있었다면, 그것은 과거 실전적인 엔터프라이즈 환경에서의 성능진단 경험을 바탕으로 한 시기적 틈새의 경쟁력이었을 것이다. 시장의 흐름에 부응하되, 기술적 깊이와 통찰력을 놓쳐서는 안된다.
경쟁력있는 솔루션으로 괄목할 만한 성장을 이룬 기업이 시장의 요구와 경쟁사 솔루션의 스펙작업에 부응하여 추가적인 잡다한 기능을 넣으면서, 솔루션이 점차 무거워지고 초기 솔루션 자체의 정체성을 잃어버림으로써 결국 망해갔다. 이를 타산지석으로 삼아 시장의 변화를 주시하되 진정 필요한 것이 무엇인가를 끊임없이 고민하여 핵심기능을 효과적인 기법으로 구현하고, 직관적이며, 경량화와 단순성을 잃지 않아야 한다.
또한, 너무 영업에만 급급한 나머지 기구매 고객사에서 대한 기술지원과 시장에서의 목소리에 귀기울이는 것을 소홀히 해서는 안된다. 기구매 고객사의 기술지원을 그 무엇보다 최우선시 하는 기술지원정책의 수립과 과감한 투자가 필요하다.
꿈꾸는 자의 승리
새로운 시장을 일구어 가는 것은 그 어떤 것보다 시대적 소명감을 요구한다. 고객을 담보로 한 무책임한 실험이어서는 안되기 때문이다. IT환경은 결국 인간을 위한 환경이다. 그렇기에 더욱 철저하고, 더욱 진실해야한다. 보다 더 바람직하고 효율적인 IT운영환경을 만들기 위해 우리는 또다시 먼 미래로의 꿈을 꾼다. 승리는 늘 꿈꾸는 자의 것이었다.
 Prev
Prev

 Rss Feed
Rss Feed